How to extract tables.
The simple answer is by using the Table selector in pdf2Data Editor.
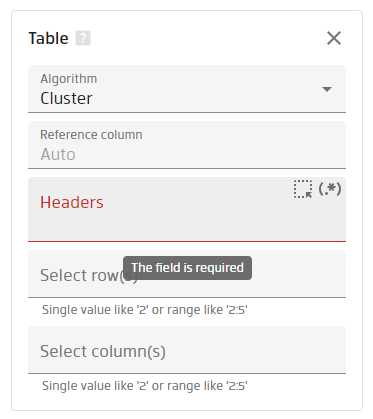
It's quite powerful and allows you to detect tables within a document and extract one you specify by either area you draw on the sample document or by the header line.
Table extraction works perfectly for many cases with the default settings, however, sometimes gives you some useless data.
There is a widely-used layout for invoices, which is basically a whole-page table with borders, and information about an invoice itself is repeated on each page.
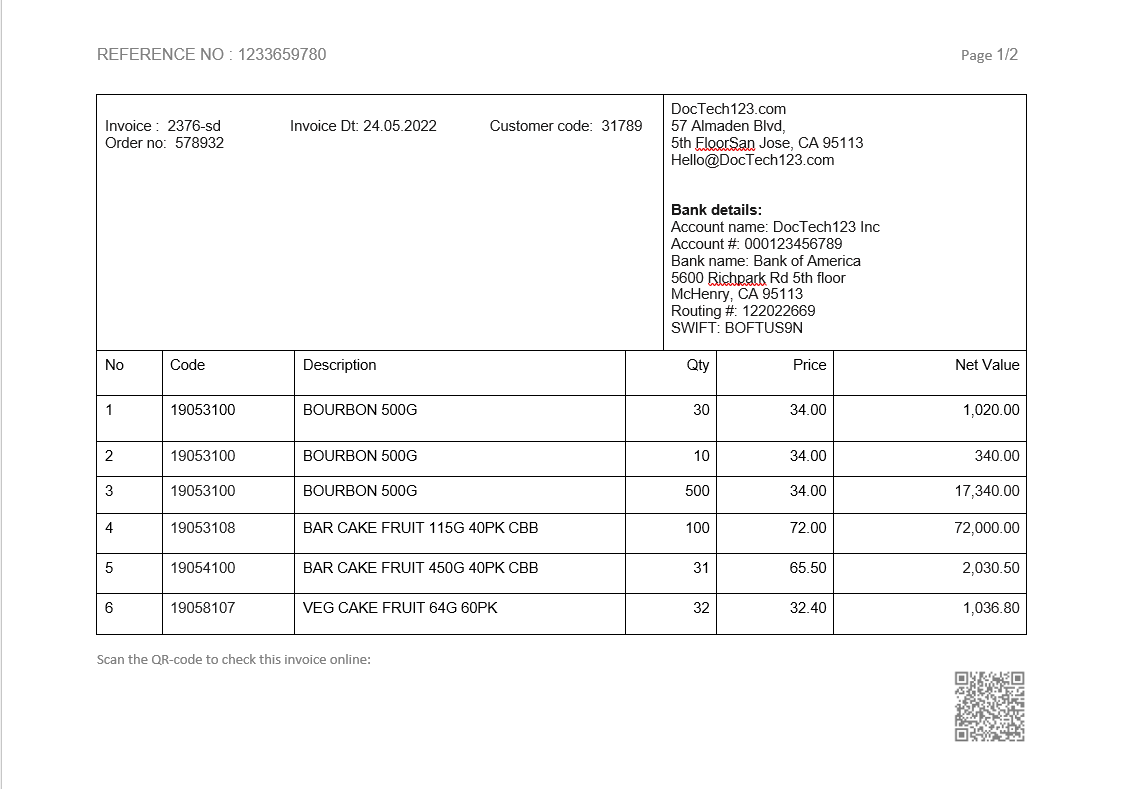
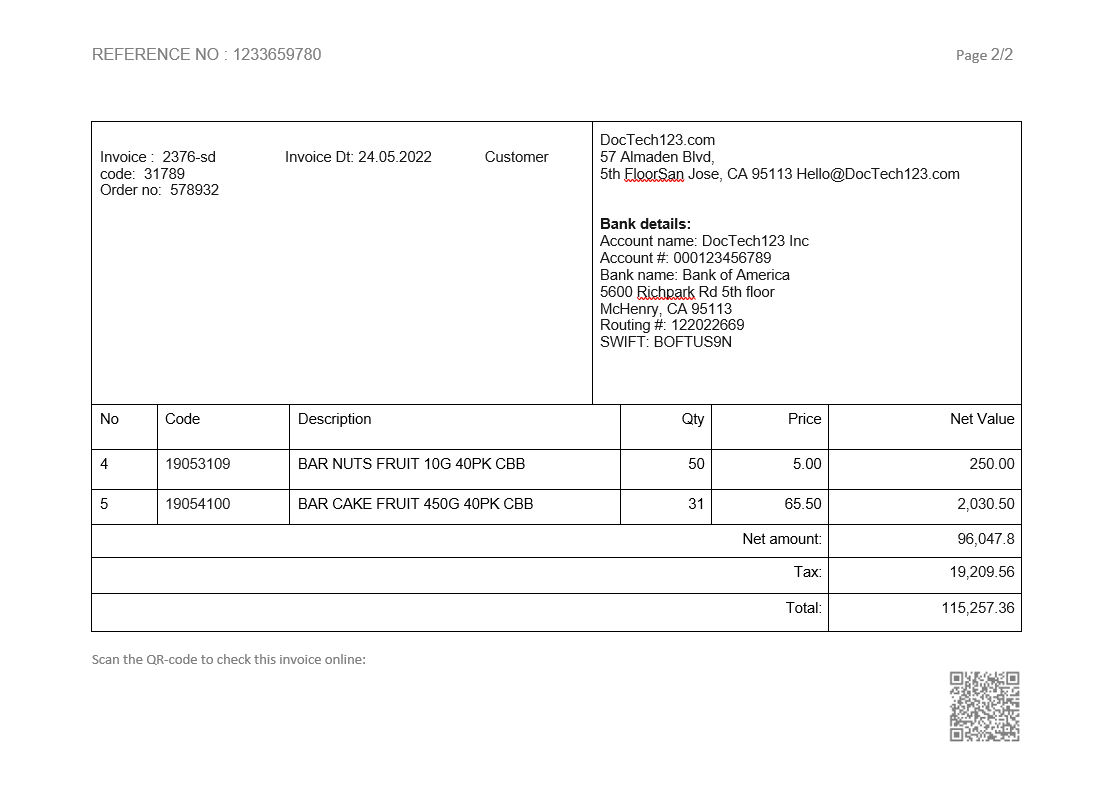
It's easy to extract those tables from each page. However, if your goal is to extract only a list of items, it will take a lot of your effort to filter out useless data. Pdf2Data Editor, particularly the table selector, can easily deal with this.
In 2 steps.
-
Use the Cluster algorithm

-
It's needed you to set up the headers of the part you want to extract. Click on the Select headers button

and select the needed line on the reference document

What you have in your parsing pipeline:
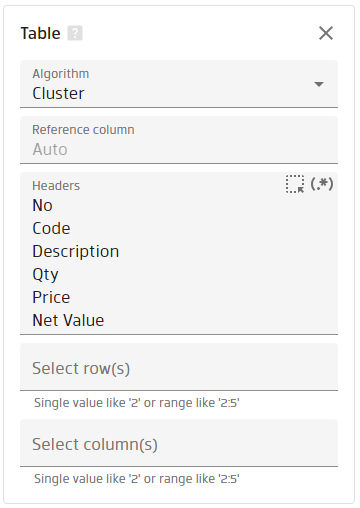
And as the results you have two found tables:
